The basic idea is to use Semantic Web technologies to support the Enterprise Architecture practice in the organisation. Semantic Web offers a set of capabilities that makes it ideal for this purpose.
What is available?
Semantic MediaWiki The current version (at the time of writing: 1.8.x) is a sufficiently mature implementation of semantic features on top of MediaWiki. There are a suite of extensions – most of them are part of the Semantic Bundle – available to extend the basic feature set.
Enterprise Architecture ontology The basis for enabling SMW to be used as an Enterprise Architecture (EA) tool is the EA ontology (call it meta-model, or schema). It defines a set of concepts and their relationships that will help to organise and structure the information gathered about the enterprise. One of these ontologies can be easily derived from the ArchiMate (V2) meta-model.
Triple storage for semantic inferencing and querying (SPARQL) Triple stores are a bit tricky in the current version of SMW. The main reason for using them is to take advantage of features like: symmetric properties and inverse properties, offering a lot of value when querying.
What else is needed?
Semantic Annotation Currently the weakest part of MediaWiki (not specific to SMW) at the moment is the editing, which is not helped by the additional markups for semantic annotation. DataWiki (formerly SMW+) a reasonable job with allowing semantic annotation on the wiki page in WYSIWYG mode. A decent annotation tool (perhaps porting DataWiki’s implementation) is needed to do this job better than the plain wiki markup in SMW. Note that most people solve this issue and prefer to use Semantic Forms to enter data. It is a good solution, but carries the danger of constraining information capture and limiting use (virtually turning SMW into SharePoint or an Access Database). This will require new development and/or porting of existing code.
Spreadsheet integration The reality is that most organisations still use and prefer Excel as the de-facto standard for gathering “somewhat” structured information. It is still the most effective way to request records of data (for example: application names, descriptions, owners, etc) and review of data in many organisations. This will require new development.
Visualisation tool Most people prefer visual representation of landscape, design, etc. and the preferred tool in most places is Visio.This will require new development.
The part in there that really caught my attention was about the common-place-book. The following historical quote from John Mason in 1745 makes the case for organised (retrievable) thoughts:
Think is not enough to furnish this Store-house of the Mind good Thoughts, but lay them up there in Order, digested or ranged under proper Subjects or Classes. That whatever Subject you have Occasion to think or talk upon you may have recourse immediately to a good Thought, which you heretofore laid up there under that Subject. So that the very Mention of the Subject may bring the Thought to hand; by which means you will carry a regular Common Place-Book in your Memory.
In the same chapter, the historian Robert Darnton is quoted on re-organising texts into fragments and removing the linearity of the text:
Unlike modern readers, who follow the flow of narrative from beginning to end, early modern Englishmen read in fits and starts and jumped from book to book. They broke texts into fragments and assembled them into new patterns by transcribing them in different sections of their notebooks. Then they reread the copies and rearranged the patterns while adding more excerpts. Reading and writing were therefore inseparable activities. They belonged to a continuous effort to make sense of things, for the world was full of signs: you could read your way through it; and by keeping an account of your readings, you made a book of your own, one stamped with your personality.
Later in the Serendipity chapter – another pattern involving accidental connections – the author mentions DEVONthink, a tool to manage and organize all those disparate pieces of information. DEVONthink features a clever algorithm that detects a subtle semantic connections between distinct passages of text.
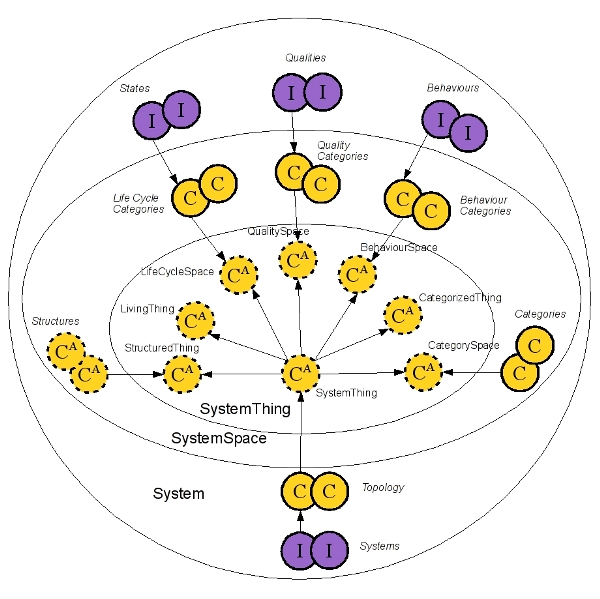
The purpose of the Systems Ontology is to provide a framework, in the form of an ontology, for capturing system details resulting from systems analysis.
The Systems Ontology is composed of three distinct parts:
SystemThing holds the core concepts of a system – not to be changed
SystemSpace is a definition of categories applicable to different concepts describing specific systems – should change rarely as the understanding of the different types of systems evolves
System is the place for the instances of specific systems – may change regularly as the analysis and understanding of specific systems progresses.
The following diagram is a representation of the different elements in each part.
Core concepts and Spaces Core concepts define the fundamental building blocks for the Systems Ontology in a set of abstract classes of mainly two types: Thing and Space. Things describe the different aspects of a system on very high abstraction level (meta-meta in this case). Spaces provide further refinement for the different aspects of a system.
Structure The structure of the system is described in abstract sub-classes of StructuredThing. The structure defines the relationships between concepts, it defines what form (in terms of graphs) of construct can be built. Constructs can be for example: chain, ring, tree, net, a combination of these or any other formation.
Specific structures are defined inheriting from the StructuredThing abstract class, making StructuredThing a collection, a container of various types.
An example structure: ComposableThing has two slots, has_part and is_part_of (both are each other’s inverse), since has_part is a multi-value, is_part_of a single-value slot referring to instances, the structure for ComposableThing is going to be a tree.
Category Categories are defined in the CategorySpace, which holds a hierarchy of categories underneath. CathegoryThing enables instances of a system elements to reference multiple categories from the CategorySpace.
CategorySpace is a bit unusual as far as modelling categories goes. Usually there is a meta-model for describing the characteristics of a category on the meta-model level then each category is an instance in the model often in some form of relationship with other categories. In this case, a different, perhaps unusual approach is taken when categories are defined as classes and sub-classes of classes. This will allows to build a hierarchy of categories and use the class name for the name of the category, which should be sufficient as no attributes are necessary. There is one more twist, instead of assigning a class (category) as a superclass to the categorized class, the CategorizedThing defines a slot with the value type of a class, in other words the category is defined as an attribute (slot).
This approach allows to define the categories in the meta-model in a hierarchy and still use them as an attribute in the model.
Life-cycle The notation of life-cycle makes the concepts “alive”, in other words, it represents the time factor.
Individual life-cycles are captured in the LifeCycleSpace as sub-classes. Life-cycles consist of states, these are captured as instances of a life-cycle class in the ontology. LiveThing enables the system instances to reference individual states and other related instances – behaviour and quality (details in the next section).
Note that life-cycles are not described as proper state-machines in this ontology. There is no notation of events or state transitions other than registering the preceding and following states for each state instance.
Behavior and Quality The following assumption was made: Only “living” things (ie concepts with life-cycle) show characteristics of behavior and qualities. Based on this assumption, behaviour and quality details can be registered to any LivingThing.
Behavior and Quality are two concepts represented in the ontology in a similar fashion. BehaviorSpace consists of sub-classes, where sub-classes are considered as categories of behavior. These categories can serve as a mechanism to group, qualify, arrange the long list of different behaviors a system may have. Specific behaviors are captured as instances of a Class from the BehaviorSpace.
Qualities are represented the same way, where categories are sub-classes of the QualitySpace and specific qualities are instances of a class from the QualitySpace.
System instances The root for capturing specific system instances is SystemSpace, it inherits a set of abstract classes (LivingThing and CategorizedThing) describing a system.
Besides creating instances for system elements a few other types of instances will be created along the way including: life-cycle states, behaviors and qualities.
States Life-cycles consist of states, individual state instances should be created under the relevant life-cycle categories. States are later referenced from system instances, where a system can only have one state at a time in the current setup of the ontology.
Behaviours and Qualities Behaviours and Qualities are instances of simple classes in the pertinent categories. In the current ontology each instance is represented with a name (slot) only. The categories should be carefully chosen for both set of concepts, otherwise can be time consuming to re-factor an instance of a quality into a category in order to register finer grain qualities. Same challenge applies to registering behaviour. Topology and Systems Systems, and sub-systems, are captured in some form of hierarchy in the ontology – the Topology. The Topology for systems is not pre-defined as it mostly depends on the method applied to systems analysis, and somewhat depends on the different types of systems as well. Topology is withing the System ontology, it is captured together with the system instances, unlike the categories for life-cycle, behaviour and quality.
System instances are created within the topology, where they automatically inherit characteristics of LivingThing and CategorizedThing. The topology does not have a notation of structure for system elements, therefore predefined (in the SystemSpace) structures should be applied as Super-classes to specific topology classes. Note that sub-classes in the topology will inherit structures from parent classes, for that reason structures should be used sparingly in classes closer to the root and should be applied to classes closer to the instances.
Data characteristics of system elements are defined within of the Topology by adding them to specific classes. Data details are essentially attributes (slots here) on a class. One should be careful making sure that data is not confused with structure. Slots with references to other system instances are perfectly valid data elements, however these can be easily confused with structure elements also represented as slots. The success of proper separation will depend on the rigour applied to systems analysis.
Key note: The Domain Specific IDE by Steve Cook (Microsoft) Steve has introduced DSLs briefly, talked about various patterns of use, then the main topic of software development using DSLs and the evolution of software development. He depicted SW evolution in quadrants and highlighted the path of evolution as: craftmanship > mass production > continuous improvement > mass customization. A few highlights from the session
It makes sense to model concerns [IT Architecture].
[DSL, code generation] the only way to get some head-way is to make it economical.
To create a language [DSL], it really means to create a tool. The language itself is pretty useless in itself.
We have recognized that Visual Studio is a platform not just an IDE.
Bran Selic: Standardization [software development] goes way beyond standardization of API. One way to do it right is to standardize on semantics.
Experience Report: Evangelizing Code Generation: A case study of incremental adoption by Brooke Hamilton (FM Global) Brooke’s session was pleasantly different than the other sessions during the conference as he was from the customer side and not a vendor or an academic. His presentation was brilliant, well structured, pleasantly constructed. Brooke had real details of his own and his team’s experience on their project(s) from the last few years. It was definitely one of the best presentations during the conference, it sparked a lot of good discussions.
Code Generation Narcosis – you feel more powerful using code generation than you really are.
Code generation improves architecture. It makes you look for redundant parts and separate concerns.
We cannot make an application serving unknown needs, but we can generate a lot of code!
Versioning of the templates [code generation] is absolutely crucial.
Tutorial: Strategies for generating code from Microsoft DSL tools and T4 text templates by Brooke Hamilton (FM Global) This session was more of a demo using the Microsoft DSL Tools in the Visual Studio environment. Brooke also tailored in some of his experience with the tool and how it is applicable to their projects at FM Global.
* * *
In summary, it was an excellent conference with a lot of great presentations from the top experts on this field, great discussions during panels, BoFs and Goldfish Bowls. A lot of new ideas, thoughts and questions to take away to consolidate and look for answers until next year’s event.
Tutorial: Model-Driven SOA: Synchronize Business Planning with the IT Design process by Ian Barnard (Telelogic) Telelogic, recently acquired by IBM, presented a very corporate like view of modeling, the key buzzwords of the session were: EA, BPM, SOA, ELM (Enterprise Lifecycle Management), Model-Driven SOA…
Tutorial: Implementation Techniques for Domain-Specific Languages by Markus Voelter (Independent) Markus is an entertaining presenter, he has a broad knowledge of the various topics around code generation and DSL. His customer experience also comes across and he makes genuine remarks about IT architectures and business-IT alignment. This particular presentation was a deep-dive on DSL and implementation, categories of DSLs and their use, DSL implementation techniques and examples including: Scala, Ruby, Converge, EMF/GMF, MetaEdit+
DSL does not have to be Turing complete!
execution != precision
Experience Report: Can executable UML make it as a Mainstream Programming Paradigm? by Allan Kennedy (Kennedy Carter) The presentation started with a fair amount of philosophical discussion, involving the audience, about software intensive systems, software engineering, and modeling. Later Allan introduced the concepts, the use and value of Executable UML (xUML). xUML seems to have impressive customer base and references including some defense industry customers and NASA.
Tutorial: Best practices for Creating Domain-Specific Modeling Languages by Juha-Pekka Tolvanen (MetaCase) JP has recently published a book on Domain Specific Modeling (DSM) and I was very much looking forward to hear the details from the author himself. JP gave plenty of examples and details on best practices, lessons learned from his extensive customer experience. A great value from the presentation was to hear concrete numbers for developing with DSL. The statistics included variations for language complexity (number of concepts) and the complexity of artefacts generated (number of them and types).
Panel: Flexibility in Code Generation chaired by Jos Warmer (Ordina), Sven Efftinge (itemis), Anneke Kleppe (CapGemini NL), Laurence Tratt (Uni of Bournemouth), Steven Kelly (MetaCase) The panel has eluded into many different topics in many directions including flexibility in DSL and code generation. From the questions and comments it seems that these concepts still have a long way to go to be more mature, precise and agreed on.
Unfortunately I’ve missed the Mistery Movie of the evening – Pirates of Silicon Valley – will catch up on that one day…
The first day passed really fast with lots of great topics and presenters. Below are a few interesting quotes and thoughts from the day.
Keynote: Matching Supply and Demand: Challenges in Model-Based Code Generation for Quality of Service-Constrained Software by Bran Selic (Malina Software Corp)
Bran‘s presentation had many thought provoking statements and questions in the domain of System Engineering with Quality of Services (Non-functional) requirements. Amongst many statements, the following was maybe the strongest hit:
Platform independent != Platform ignorant
Direct Code Generation with Built-in Flexibility by Anneke Kleppe (CapGemini NL)
An interesting talk about hard-coded (programmatic) transformations. She was talking mostly about the Octopus project. She emphasized a lot the importance of decomposition on many levels including not only the target application but also the code generator.
DSL model is not a DSL! Just like a .java file is not the Java language
is a reminder of how misused terminology and jargon has polluted not only this domain [DSL] but the whole IT industry.
Panel: MDD and Software Product Lines – a marriage made in heaven? Mark Dalgarno (Software Acumen), Juha-Pekka Tolvanen (MetaCase), Ian Barnard (Telelogic), Markus Voelter (independent)
On the volatility of investment in DSL and code generators (somebody from the audience):
The value of information captured in models (instances) is orders of magnitude larger than the investment in the meta-model, transformation, tools.
Goldfish Bowl: Approaches to DSL Evolution chaired by Peter Bell
First of all the concept of a goldfish bowl discussion is brilliant! I do not know how these work generally but this instance of it went very-very well.
The discussions were mainly skirting around the situations where the DSL changes. The typical questions came up were:
What happens to the existing model instances?
What happens to the existing code generators?
Is there a way to make the transition (evolution) automated?
Tutorial: Concrete Syntaxes of DSLs by Arno Haase (Haase Consulting) and Sven Effinge (itemis)
It was a fairly basic overview of various DSL and DSM approaches with a demo of openArchitectureWare‘s tools. The demo was a nice example of using textual modelers (xText) together with graphical editors (GMF).
Birds of a Feather: The Art of Abstraction
The main theme for this BoF was to list and discuss the considerations that make a DSL a good DSL.
What is a ground-breaking new idea? a killer app? a real innovative idea? Every new idea, anything innovative has roots in something existing, something already invented. Is everything just an evolution of other things, there is nothing innovative? How far one should really go back to the roots?
Is it enough to come up with a great, innovative idea? What happens to the solution-for-every-problem-world-peace-and-cure-for-everything ideas? I have got a great idea, what’s next?
Where is creativity coming from? are there geniuses amongst us? is there a special food/drink or a special ritual to unleash creativity?
Read it once because it is simply a great read – not sure about the humour though
Read it every time you have a worthy innovative idea – amazing how much you will find the book related to your idea
Read it if you are frustrated about how large corporates treat innovation(especially if you are working for one) – you will find your answer in the book, not necessarily the one you wanted to hear though
Read it if you like anecdotes, stories and lessons learned – do not forget to follow up with the many references to other books, articles, Web sites and pages