There is simplicity in the scope, time, cost trinity.
There is always more to talk about, factor in, consider.
Quality, however, is part of scope!
There is simplicity in the scope, time, cost trinity.
There is always more to talk about, factor in, consider.
Quality, however, is part of scope!
Imagine…
You are a techie in a corporate.
The platform you are working on offers a vast range of tools and capabilities.
You find the next task/user story/requirement to work on.
You immediately think of a way to implement a solution to complete the task and tick the box.
You have choices…
OR
If you are an individual contributor, your choices will be limited.
If you are managing a team, then and ask yourself – What can I do to foster the former behaviour over the latter?
Either way, if you feel conflicted about this and prefer to have you and your team showing high productivity on some dashboard, then send a link to this article to your superiors.
Designs suffer from
Challenging these should be part of the behaviour.
People need to appreciate that they are working in a shared environment.
They should not feel interrogated or confronted, it should be natural, and they should feel comfortable discussing these.
Make it part of every design discussions.
Make time for it.
Make it part of the culture.
Back in 2017 Google Portfolios landed on the Google graveyard. It was a smart addition to Google Finance where you could track a portfolio and its performance over time. Even new services and migration offerings sprung up seeing the gap Google left.
If there was one function I miss, it was the interactive portfolio performance graph with benchmarks.
It turns out a simple one is really not that hard once you have Python and Pandas in your tool-belt.
I started with is a set of transactions in Excel.
I wanted to be able to
I did not need a web application, so I went with the next best thing – a Jupyter notebook.
Ran Aroussi’s yfinance package for python makes it easy to grab end of day trading data including stock tickers and currency pairs.
Pandas is excellent for dealing with time-series data.
The essence of the approach is
Plotly draws great interactive charts inside Jupyter.
The latest version of the notebook is now hosted on GitHub:designfultech/portfolio_tracker.
I am planning to add portfolio analysis to the notebook, something like pyfolio’s tearsheets from Quantopian.
Infrastructure as Code (IaC) as in cloud infrastructure, not infrastructure code as in writing your own middleware library.
In most cases IaC refers to some kind of template-based solution.
Template in this article refers to AWS CloudFormation template
It is strongly debatable if templates are code. If anything, code inside templates is generally an anti-pattern.
Think of templates as an “intermediary language” rather than code.
Templates are executed by respective platform “engines” driving actual cloud infrastructure configuration management.
Consider it “code” as far as an asset managed in version control together with the rest of the source code.
Templates will be sufficient for most infrastructure (IaC) jobs. Most templating languages will have constructs to express logic, for example: conditions. Most will also allow to include inline code as part of the configuration, nonetheless it is code mixed with template, for example: AWS velocity template for DynamoDB.
Writing Infrastructure as Code templates this way – in YAML or JSON – has been reasonable, but not without concerns. A good article on the topic is In defense of YAML.
The AWS SAM is a good example of simplifying CloudFormation templates, notice the Transform: 'AWS::Serverless-2016-10-31' elements in SAM. A single SAM element may transform into a list of CloudFormation elements deploying a series of resources as a result.
Another example is serverless.com their templating language supports multiple platforms while also simplifies the templating compared to CloudFormation.
One of my concerns however is the mixing of Infrastructure as Code with Function as a Service definitions. For example, the definition of a function AWS::Serverless::Function in the same place with an Gateway API AWS::Serverless::Api and related Usage Plan AWS::ApiGateway::UsagePlan.
I would like to keep application and infrastructure concerns separate.
My immediate approach was going to be to split up the template into multiple files and use AWS::Include to bring them back together.AWS::Include does not work for all parts of the schema. Trying to use AWS:Include under Resources to include a set of functions simply does not work.
Next approach was going to be Nested Stacks. It is the recommended approach for large stacks anyway, so it seemed like a winner. It turns out Nested stacks are great for reusable templates – see Use Nested Stacks to Create Reusable Templates and Support Role Specialization – not so much for decomposing an application (template).
The AWS API gives access to the platform and resources through a range of SDK-s (Python SDK is called boto3). It is truly a low level access to resources that is typically used for developing software on the platform.
Infrastructure could be managed using the SDK. There are many good automation examples on how AWS Lambda can react to events from the infrastructure and respond with changes to it.
Managing more than a few resources using the SDK is not feasible, considering the coordination it would require: dependencies, delay in resource setup.
The troposphere library allows for easier creation of the AWS CloudFormation JSON by writing Python code to describe the AWS resources.
The GitHub project has many good examples
The examples would led you to believe that using troposphere is not much different than writing a CloudFront or SAM template in Python. Depending on your use case however, there are opportunities to explore:
Having the infrastructure and deployment configuration close to the implementation code has its own pros and cons.
Ideally troposphere would only be used in development time (not runtime if we can avoid it), therefore the deployment package would not include this library.
# Development requirements, not for Lambda runtime
# pip install -r requirements-dev.txt
awacs==0.9.0
troposphere==2.4.6I use template.py in the root of the project, the same place where the template.yaml (or .json) would be, for producing the CloudFormation template.
I have followed two patterns for defining platform resources in the source code.
The resource definitions are part of the class implementation.
Note that the troposphere library is only imported at the time of getting the resources. Then it is only used when generating the CloudFormation template. None of these would need to run in the lambda runtime.
# the application component
class ApplicationComponent(...):
# class attributes and methods
# ...
@classmethod
def cf_resources(cls):
from troposphere import serverless
# return an array of resources associated with the application component
return [...]
# the template generator
from troposphere import Template
t = Template()
t.set_transform('AWS::Serverless-2016-10-31')
for r in ApplicationComponent.cf_resources():
t.add_resource(r)
print(t.to_yaml())I use decorators for Lambda function implementations. The decorator registers a function (on the function) returning the associated resources (array).
# the wrapper
def cf_function(**func_args):
def wrap(f):
def wrapped_f(*args, **kwargs):
return f(*args, **kwargs)
def cf_resources():
from troposphere import serverless
# use relevant arguments from func_args
f = serverless.Function(...) # include all necessary parameters
# add any other resources
return [f]
wrapped_f.cf_resources = cf_resources
return wrapped_f
return wrap
# the lambda function definition
@cf_function(...) # add any arguments
def lambda1(event, context):
# implementation
return {
'statusCode': 200
}
# the template generator
from troposphere import Template
t = Template()
t.set_transform('AWS::Serverless-2016-10-31')
for r in lambda1.cf_resources():
t.add_resource(r)
print(t.to_yaml())
You could implement lambda handlers in classes by wrapping them as Ben Kehoeshows in his [Gist]
(https://gist.github.com/benkehoe/efb75a793f11d071b36fed155f017c8f).
AWS recently released the alpha version of their Cloud Development Kit (CDK). I have not tried it yet, but the Python CDK looks super similar to troposphere. Of course, they both represent the same CloudFormation resource definition in Python.
troposphere or AWS CDK, they both bring a set of new use cases for managing cloud infrastructure and let us truly define Infrastructure as Code.
I will explore the use of troposphere on my next project.
The AWS SAM and CloudFormation mix works well for my projects.
I have been working mainly with Python for building Lambda functions on AWS.
However, managing code from project to production has been less than trivial.
AWS Lambda Deployment Package in Python
This article and the sample project on GitHub shows how to
A sample project demonstrating this approach is at GitHub:designfultech/python-aws
Building and deploying JavaScript functions using SAM was super simple – see Watcher project.
SAM’s original project structure for Python is less than ideal.
virtualenv for development and define different dependencies (requirements.txt) for the runtime.I use the Pycharm IDE for development. My projects have their own virtual environments, and I use the following project structure.
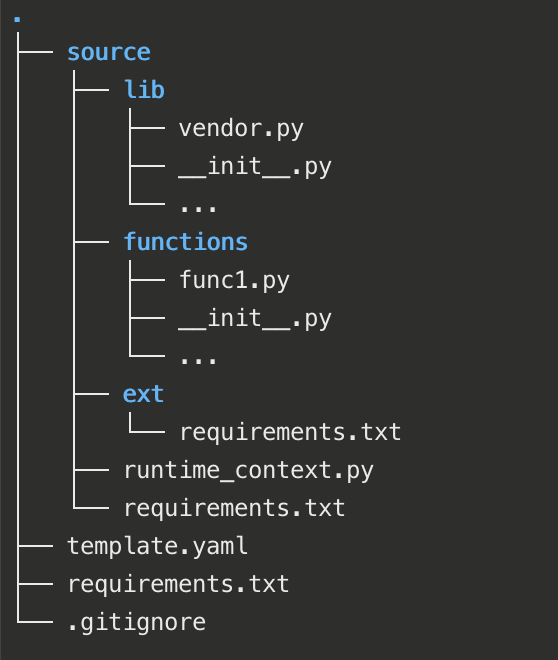
Where
SAM buildSAM build for the deploymentVendoring is a technique to incorporate 3rd party packages, dependencies into the project. It is a neat trick used in other languages, and this specific one is adopted from Google’s App Engine library.
ext. Add ext to your Python path so dependencies resolve during development.ext for the deployed runtime.ext directory.pip install -t . -r requirements.txt ext directory available to the runtime?/lib/vendor.pyruntime_context.py in the root of the projectimport os from lib import vendor vendor.add(os.path.join(os.path.dirname(os.path.realpath(__file__)), 'ext'))extdirectory needs a single line of import.import runtime_context I use the runtime_context.py to setup vendoring for all functions.
I also place shared configurations and variables here, for example:
import logging LOGGER = logging.getLogger()
LOGGER.setLevel(logging.DEBUG)
import os
GREETING = os.environ.get('GREETING', 'Hello World!')The approach and project structure described here works for development, local test with SAM, and AWS runtime.
When deploying to AWS, run the SAM CLI from the root of the project, where the template file is. Use a distribution directory dist for building and packaging.
cd source/ext pip install -r requirements.txtsam build --template template.yaml --build-dir ./dist[BUCKET_NAME] is the name for the bucket where the deployment artefacts are uploaded.sam package --s3-bucket [BUCKET_NAME] --template-file dist/template.yaml\
--output-template-file dist/packaged.yaml[STACK_NAME] is the name of the stack for the deployment.aws cloudformation deploy --template-file dist/packaged.yaml\
--stack-name [STACK_NAME] --s3-bucket [BUCKET_NAME]When done with the application, un-dpeloy it by removing the stack.
aws cloudformation delete-stack --stack-name PythonAppStackThis is just one approach that works for me. There are probably numerous other ways to make coding Python functions easy and comfortable.
Filestore is a cloud file storage API backed by S3. The project includes a sample client based on FilePond.
User guide, source code and deployment instructions for AWS are available on GitHub:designfultech/filestore-aws
I wanted to use the latest Python – 3.7 – for coding.
Avoiding infrastrucutre code was a key principle for the project. I also wanted to avoid the use of 3rd party libraries if possible.
CloudFormation and SAM templates – in YAML – has worked very well in past projects, and so did for this one.
API definitions were written in Swagger (OpenAPI 2.0) – in YAML.
I wanted to use S3’s API directly for uploads and downloads.
Ideally the app would be running behind a domain setup on Route 53, this setup is not included in the project for now.
Tha application builds upon a key platform capability: S3’s presigned URL-s.
Presigned URL-s allow anyone – unauthenticted users – to access S3 objects for a specified duration. In this case the application allows upload (PUT) and download (GET) of S3 objects.
Presigned URL-s also allow the client to use S3’s API directly. There is no need to go through Lambda for uploading or downloading files, which could incure high costs.
Since Lambda’s cost is time based, large amount of data transfer over slow connection would eat up a lot of compute time.
Review the Building the Watcher [Serverless app] for details on:
Python has first class support on the platform. The AWS SDK is known as Boto 3and it is bundled with the Lambda runtime environment, no need to include as a dependency. However, Lambda does not include the very latest version of the Boto3 library (at the time of this writing).
UPDATE: SAM’s support for Python has a few gotchas when including 3rd party libraries. More about this in the article dedicated to AWS Lambda in Python.
The diagram shows all services included in the app.
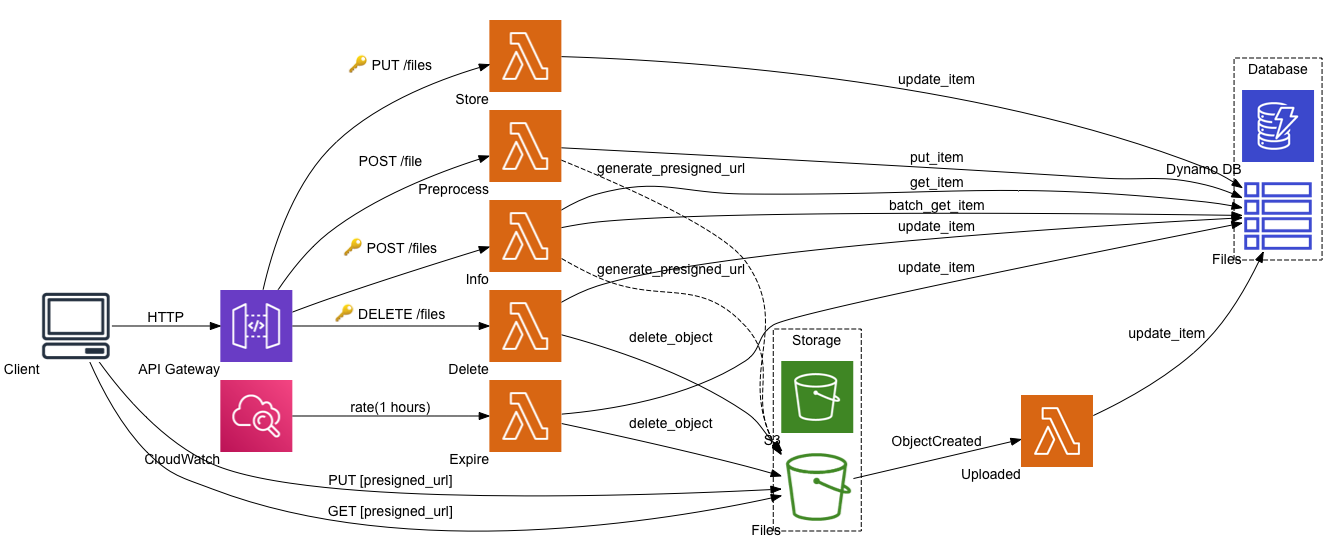
Aside from the S3 service and bucket, there isn’t anything new compared to the previous project Building the Watcher [Serverless app] on AWS.
I was hoping to make use of an Object Mapper library that abstracts away the DynamoDB low-level API. There are a few good candidates out there such as PynamoDB and Flywheel.
After a short evaluation, I ended up coding up my own lightweight, albeit less generic abstraction, see /source/lib/ddb.py.
On a larger project with multiple entities I would definitely use one of the OM libraries.
I originally wanted to build the application to support multi-tenancy, but decided to leave that for another project where it would make more sense. However supporting some of the multi-tenant strategies (SaaS Solutions on AWS: Tenant Isolation Architectures) with these libraries is not trivial, or simply not possible – something to remember.
The S3 API is significantly simpler than the DynamoDB API. It was simple enough to use directly from the functions without any abstraction.
When I started, I did not realise S3 uploads recognise the mime-type of the files. I was going to use python-magic for this magic.from_buffer.
It turned out is not necessary as S3 objects have a ContentType attribute for this.
file_object = S3_CLIENT.get_object(Bucket=..., Key=...)
content_type = file_object.get('ContentType')The file uploads do not preserve the original file name when placed into S3, they have the same name as the DynamoDB key. When the Presigned URL is generated for the download, using the ResponseContentDisposition attribute can set the file name for the download.
AWS Lambda supports a range of S3 events as triggers. This, and all the other event sources, make the AWS platform and the Serverless model really powerful.
The application uses the s3:ObjectCreated event to update the DynamoDB item with properties of the s3 object (file) such as size and mime-type.
Most likely the browser client is going to be on a different domain than the API and S3, therefore CORS settings are necessary to make this application work.
There are two steps for the API to work with CORS:
Access-Control-Allow-Origin header in the Lambda response.CORS configuration for S3 resources has a specific place in the CloudFormation template: CorsConfiguration.
If the application is configured at the time of deployment to store uploads immediately – StoreOnLoad=True – then the FileExpireFunction function is not needed.
CloudFormation Condition facility allows control over what gets deployed, amongst other conditional behaviours. In this project, depending on the parameter value, the expire function may or may not get deployed.
Conditions:
CreateExpirationScheduler: !Equals [ !Ref StoreOnLoad, False ]
...
Resources:
FileExpireFunction:
Type: AWS::Serverless::Function
Condition: CreateExpirationScheduler
Properties:
...I picked FilePond for browser client. It offers a high degree of customisation, and comes with a good set of capabilities.
The server API interaction had to be customised to work with the Filestore and S3 API-s. I implemented the customisation in a wrapper library – static/web/uploader.js. It takes care of the uploading (process) and deleting (revert) of files.
The sample webpage and form static/web/index.html is built using jQuery and Bootstrap to keep it simple. The form has a single file upload managed by the FilePond widget. In this example there is no backend to pick up the data from the form.
See the README.md Web app client section for more details on how to deploy the sample web app client on S3 as a static site.
I have experimented two types of tests for this project: unit and integration.
Unit tests are fairly straightforward in Python. The interesting bit here is the stubbing of AWS services for the tests. botocore has a Stubber class that can stub practically any service in AWS.
There is one unit test implemented for the preprocess function, which shows how to stub the DynamoDB and S3 services.
import boto3
from botocore.stub import Stubber
ddb_stubber = Stubber(boto3.client('dynamodb'))
s3_stubber = Stubber(boto3.client('s3'))See tests/unit/file.py for more detail on the specific test code.
I have found Tavern ideal for most of my integration testing scenarios.
REST API testing has first class support. Defining tests with multiple steps (stages) in YAML is easy.
There are 4 integration tests defined: upload, store, delete, download. These tick the boxes on the preprocess, store, delete, info, uploaded functions. However it does not help with testing functions like expire which is triggered by a scheduled event only.
Tavern can pick up and use environment variables in the scripts. See the README.md Test section for more details on how to setup and run the integration tests.
I am reluctant to add a REST endpoint to functions such as expire just for the sake of testability.
The aws CLI can invoke Lambda functions directly and so can Boto 3 via an API call – Lambda.Client.invoke. If there was a way to include non-REST Lambda function invocations in Tavern test cases, that would be ideal.
Tavern supports plugins for adding new protocols – it has REST and MQTT added already. I wonder if it is feasible to build a plugin to support Lambda invocations?
The serverless architecture worked very well for this app.
In the end the amount of code was relatively small considering the functionality the app provides.