The application
Filestore is a cloud file storage API backed by S3. The project includes a sample client based on FilePond.
User guide, source code and deployment instructions for AWS are available on GitHub:designfultech/filestore-aws
Planning
I wanted to use the latest Python – 3.7 – for coding.
Avoiding infrastrucutre code was a key principle for the project. I also wanted to avoid the use of 3rd party libraries if possible.
CloudFormation and SAM templates – in YAML – has worked very well in past projects, and so did for this one.
API definitions were written in Swagger (OpenAPI 2.0) – in YAML.
I wanted to use S3’s API directly for uploads and downloads.
Ideally the app would be running behind a domain setup on Route 53, this setup is not included in the project for now.
Presigned URL-s with S3
Tha application builds upon a key platform capability: S3’s presigned URL-s.
Presigned URL-s allow anyone – unauthenticted users – to access S3 objects for a specified duration. In this case the application allows upload (PUT) and download (GET) of S3 objects.
Presigned URL-s also allow the client to use S3’s API directly. There is no need to go through Lambda for uploading or downloading files, which could incure high costs.
Since Lambda’s cost is time based, large amount of data transfer over slow connection would eat up a lot of compute time.
Getting started
Review the Building the Watcher [Serverless app] for details on:
- Approach to infrastructure as code and SAM’s intricacies
- API Design and Swagger specifics
- Cross-cutting concerns: securing API with a key
AWS Lambda in Python
Python has first class support on the platform. The AWS SDK is known as Boto 3and it is bundled with the Lambda runtime environment, no need to include as a dependency. However, Lambda does not include the very latest version of the Boto3 library (at the time of this writing).
UPDATE: SAM’s support for Python has a few gotchas when including 3rd party libraries. More about this in the article dedicated to AWS Lambda in Python.
Platform services
The diagram shows all services included in the app.
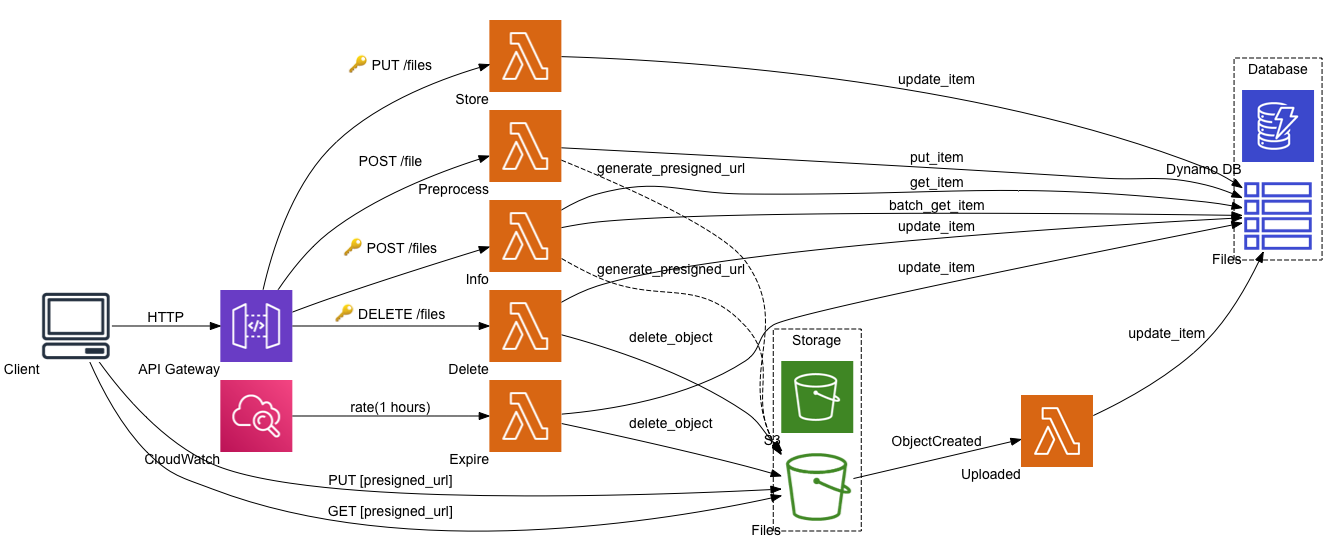
Aside from the S3 service and bucket, there isn’t anything new compared to the previous project Building the Watcher [Serverless app] on AWS.
Working with DynamoDB
I was hoping to make use of an Object Mapper library that abstracts away the DynamoDB low-level API. There are a few good candidates out there such as PynamoDB and Flywheel.
After a short evaluation, I ended up coding up my own lightweight, albeit less generic abstraction, see /source/lib/ddb.py.
On a larger project with multiple entities I would definitely use one of the OM libraries.
I originally wanted to build the application to support multi-tenancy, but decided to leave that for another project where it would make more sense. However supporting some of the multi-tenant strategies (SaaS Solutions on AWS: Tenant Isolation Architectures) with these libraries is not trivial, or simply not possible – something to remember.
AWS S3 (Simple Storage Service)
The S3 API is significantly simpler than the DynamoDB API. It was simple enough to use directly from the functions without any abstraction.
Mime-type
When I started, I did not realise S3 uploads recognise the mime-type of the files. I was going to use python-magic for this magic.from_buffer.
It turned out is not necessary as S3 objects have a ContentType attribute for this.
file_object = S3_CLIENT.get_object(Bucket=..., Key=...)
content_type = file_object.get('ContentType')Download
The file uploads do not preserve the original file name when placed into S3, they have the same name as the DynamoDB key. When the Presigned URL is generated for the download, using the ResponseContentDisposition attribute can set the file name for the download.
Events
AWS Lambda supports a range of S3 events as triggers. This, and all the other event sources, make the AWS platform and the Serverless model really powerful.
The application uses the s3:ObjectCreated event to update the DynamoDB item with properties of the s3 object (file) such as size and mime-type.
CORS
Most likely the browser client is going to be on a different domain than the API and S3, therefore CORS settings are necessary to make this application work.
API
There are two steps for the API to work with CORS:
- Create an endpoint for the OPTIONS and return the necessary CORS headers. The API Gateway makes this very easy using a mock integration.
This is configured in the Swagger API definition. - Return the
Access-Control-Allow-Originheader in the Lambda response.
S3
CORS configuration for S3 resources has a specific place in the CloudFormation template: CorsConfiguration.
Conditional deployment
If the application is configured at the time of deployment to store uploads immediately – StoreOnLoad=True – then the FileExpireFunction function is not needed.
CloudFormation Condition facility allows control over what gets deployed, amongst other conditional behaviours. In this project, depending on the parameter value, the expire function may or may not get deployed.
Conditions:
CreateExpirationScheduler: !Equals [ !Ref StoreOnLoad, False ]
...
Resources:
FileExpireFunction:
Type: AWS::Serverless::Function
Condition: CreateExpirationScheduler
Properties:
...Browser Client
I picked FilePond for browser client. It offers a high degree of customisation, and comes with a good set of capabilities.
The server API interaction had to be customised to work with the Filestore and S3 API-s. I implemented the customisation in a wrapper library – static/web/uploader.js. It takes care of the uploading (process) and deleting (revert) of files.
The sample webpage and form static/web/index.html is built using jQuery and Bootstrap to keep it simple. The form has a single file upload managed by the FilePond widget. In this example there is no backend to pick up the data from the form.
See the README.md Web app client section for more details on how to deploy the sample web app client on S3 as a static site.
Testing
I have experimented two types of tests for this project: unit and integration.
Unit test
Unit tests are fairly straightforward in Python. The interesting bit here is the stubbing of AWS services for the tests. botocore has a Stubber class that can stub practically any service in AWS.
There is one unit test implemented for the preprocess function, which shows how to stub the DynamoDB and S3 services.
import boto3
from botocore.stub import Stubber
ddb_stubber = Stubber(boto3.client('dynamodb'))
s3_stubber = Stubber(boto3.client('s3'))See tests/unit/file.py for more detail on the specific test code.
Integration test
I have found Tavern ideal for most of my integration testing scenarios.
REST API testing has first class support. Defining tests with multiple steps (stages) in YAML is easy.
There are 4 integration tests defined: upload, store, delete, download. These tick the boxes on the preprocess, store, delete, info, uploaded functions. However it does not help with testing functions like expire which is triggered by a scheduled event only.
Tavern can pick up and use environment variables in the scripts. See the README.md Test section for more details on how to setup and run the integration tests.
What about the non-REST API-s?
I am reluctant to add a REST endpoint to functions such as expire just for the sake of testability.
The aws CLI can invoke Lambda functions directly and so can Boto 3 via an API call – Lambda.Client.invoke. If there was a way to include non-REST Lambda function invocations in Tavern test cases, that would be ideal.
Tavern supports plugins for adding new protocols – it has REST and MQTT added already. I wonder if it is feasible to build a plugin to support Lambda invocations?
Final thoughts on the architecture
The serverless architecture worked very well for this app.
In the end the amount of code was relatively small considering the functionality the app provides.