The AWS SAM and CloudFormation mix works well for my projects. I have been working mainly with Python for building Lambda functions on AWS. However, managing code from project to production has been less than trivial. AWS Lambda Deployment Package in Python
This article and the sample project on GitHub shows how to
structure a Python project for Serverless functions,
Building and deploying JavaScript functions using SAM was super simple – see Watcher project. SAM’s original project structure for Python is less than ideal.
3rd party libraries, dependencies, are expected to be in the project root.
All project assets in the root will be deployed.
I want to maintain a virtualenv for development and define different dependencies (requirements.txt) for the runtime.
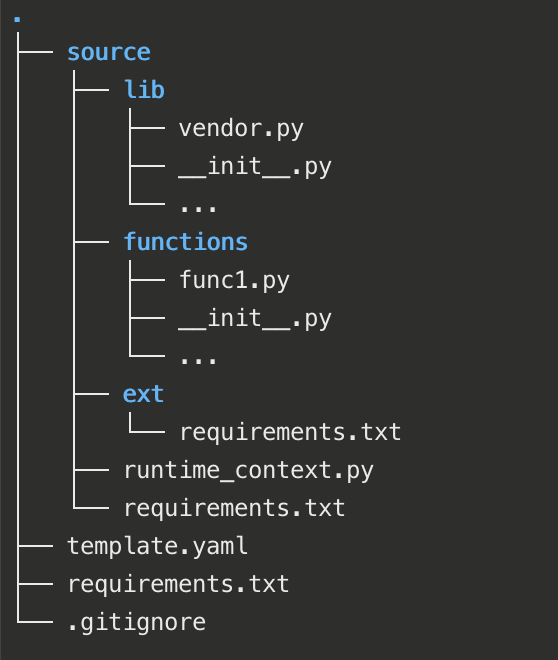
Project structure
I use the Pycharm IDE for development. My projects have their own virtual environments, and I use the following project structure.
Where
source has all the deployable source code
ext 3rd party libraries, not a Python package
requirements.txt – use it to install dependencies
lib keeps my own shared libraries
init.py it is a Python package
vendor.py library for vendoring, more on this later
functions all function(s) code
__init.py it is a Python package
I may add other packages like models for ORM
runtime_context.py more on this later
requirements.txt this one is kept empty for SAM build
dist is created by SAM build for the deployment
requirements.txt development-time dependencies for the project
template.yaml AWS serverless application template
Vendoring
Vendoring is a technique to incorporate 3rd party packages, dependencies into the project. It is a neat trick used in other languages, and this specific one is adopted from Google’s App Engine library.
Create a directory in the root of the project for the 3rd party packages ext. Add ext to your Python path so dependencies resolve during development.
Create and maintain the requirements.txt inside ext for the deployed runtime.
Install the packages in the ext directory. pip install -t . -r requirements.txt
How to make the code in the ext directory available to the runtime? This is where Google’s helper – google.appengine.ext.vendor – comes in. It adjusts the path for the Python runtime.
Add the code to a project file, for example: /lib/vendor.py
My approach is then to create the runtime_context.py in the root of the project import os from lib import vendor vendor.add(os.path.join(os.path.dirname(os.path.realpath(__file__)), 'ext'))
Any Python application that needs access to the packages in the extdirectory needs a single line of import. import runtime_context
Using the runtime_context.py
I use the runtime_context.py to setup vendoring for all functions. I also place shared configurations and variables here, for example:
The approach and project structure described here works for development, local test with SAM, and AWS runtime.
When deploying to AWS, run the SAM CLI from the root of the project, where the template file is. Use a distribution directory dist for building and packaging.
Install the 3rd party modules
cd source/ext pip install -r requirements.txt
Build the function
sam build --template template.yaml --build-dir ./dist
Package the function [BUCKET_NAME] is the name for the bucket where the deployment artefacts are uploaded.
sam package --s3-bucket [BUCKET_NAME] --template-file dist/template.yaml\
--output-template-file dist/packaged.yaml
Deploy the function [STACK_NAME] is the name of the stack for the deployment.
I wanted to use the latest Python – 3.7 – for coding.
Avoiding infrastrucutre code was a key principle for the project. I also wanted to avoid the use of 3rd party libraries if possible.
CloudFormation and SAM templates – in YAML – has worked very well in past projects, and so did for this one. API definitions were written in Swagger (OpenAPI 2.0) – in YAML.
I wanted to use S3’s API directly for uploads and downloads.
Ideally the app would be running behind a domain setup on Route 53, this setup is not included in the project for now.
Presigned URL-s with S3
Tha application builds upon a key platform capability: S3’s presigned URL-s.
Presigned URL-s allow anyone – unauthenticted users – to access S3 objects for a specified duration. In this case the application allows upload (PUT) and download (GET) of S3 objects.
Presigned URL-s also allow the client to use S3’s API directly. There is no need to go through Lambda for uploading or downloading files, which could incure high costs. Since Lambda’s cost is time based, large amount of data transfer over slow connection would eat up a lot of compute time.
Approach to infrastructure as code and SAM’s intricacies
API Design and Swagger specifics
Cross-cutting concerns: securing API with a key
AWS Lambda in Python
Python has first class support on the platform. The AWS SDK is known as Boto 3and it is bundled with the Lambda runtime environment, no need to include as a dependency. However, Lambda does not include the very latest version of the Boto3 library (at the time of this writing).
UPDATE: SAM’s support for Python has a few gotchas when including 3rd party libraries. More about this in the article dedicated to AWS Lambda in Python.
Platform services
The diagram shows all services included in the app.
I was hoping to make use of an Object Mapper library that abstracts away the DynamoDB low-level API. There are a few good candidates out there such as PynamoDB and Flywheel.
After a short evaluation, I ended up coding up my own lightweight, albeit less generic abstraction, see /source/lib/ddb.py. On a larger project with multiple entities I would definitely use one of the OM libraries.
I originally wanted to build the application to support multi-tenancy, but decided to leave that for another project where it would make more sense. However supporting some of the multi-tenant strategies (SaaS Solutions on AWS: Tenant Isolation Architectures) with these libraries is not trivial, or simply not possible – something to remember.
AWS S3 (Simple Storage Service)
The S3 API is significantly simpler than the DynamoDB API. It was simple enough to use directly from the functions without any abstraction.
Mime-type
When I started, I did not realise S3 uploads recognise the mime-type of the files. I was going to use python-magic for this magic.from_buffer. It turned out is not necessary as S3 objects have a ContentType attribute for this.
The file uploads do not preserve the original file name when placed into S3, they have the same name as the DynamoDB key. When the Presigned URL is generated for the download, using the ResponseContentDisposition attribute can set the file name for the download.
Events
AWS Lambda supports a range of S3 events as triggers. This, and all the other event sources, make the AWS platform and the Serverless model really powerful. The application uses the s3:ObjectCreated event to update the DynamoDB item with properties of the s3 object (file) such as size and mime-type.
CORS
Most likely the browser client is going to be on a different domain than the API and S3, therefore CORS settings are necessary to make this application work.
API
There are two steps for the API to work with CORS:
Create an endpoint for the OPTIONS and return the necessary CORS headers. The API Gateway makes this very easy using a mock integration. This is configured in the Swagger API definition.
Return the Access-Control-Allow-Origin header in the Lambda response.
S3
CORS configuration for S3 resources has a specific place in the CloudFormation template: CorsConfiguration.
Conditional deployment
If the application is configured at the time of deployment to store uploads immediately – StoreOnLoad=True – then the FileExpireFunction function is not needed.
CloudFormation Condition facility allows control over what gets deployed, amongst other conditional behaviours. In this project, depending on the parameter value, the expire function may or may not get deployed.
I picked FilePond for browser client. It offers a high degree of customisation, and comes with a good set of capabilities.
The server API interaction had to be customised to work with the Filestore and S3 API-s. I implemented the customisation in a wrapper library – static/web/uploader.js. It takes care of the uploading (process) and deleting (revert) of files.
The sample webpage and form static/web/index.html is built using jQuery and Bootstrap to keep it simple. The form has a single file upload managed by the FilePond widget. In this example there is no backend to pick up the data from the form.
See the README.mdWeb app client section for more details on how to deploy the sample web app client on S3 as a static site.
Testing
I have experimented two types of tests for this project: unit and integration.
Unit test
Unit tests are fairly straightforward in Python. The interesting bit here is the stubbing of AWS services for the tests. botocore has a Stubber class that can stub practically any service in AWS.
There is one unit test implemented for the preprocess function, which shows how to stub the DynamoDB and S3 services.
See tests/unit/file.py for more detail on the specific test code.
Integration test
I have found Tavern ideal for most of my integration testing scenarios.
REST API testing has first class support. Defining tests with multiple steps (stages) in YAML is easy.
There are 4 integration tests defined: upload, store, delete, download. These tick the boxes on the preprocess, store, delete, info, uploaded functions. However it does not help with testing functions like expire which is triggered by a scheduled event only.
Tavern can pick up and use environment variables in the scripts. See the README.mdTest section for more details on how to setup and run the integration tests.
What about the non-REST API-s?
I am reluctant to add a REST endpoint to functions such as expire just for the sake of testability.
The aws CLI can invoke Lambda functions directly and so can Boto 3 via an API call – Lambda.Client.invoke. If there was a way to include non-REST Lambda function invocations in Tavern test cases, that would be ideal. Tavern supports plugins for adding new protocols – it has REST and MQTT added already. I wonder if it is feasible to build a plugin to support Lambda invocations?
Final thoughts on the architecture
The serverless architecture worked very well for this app. In the end the amount of code was relatively small considering the functionality the app provides.
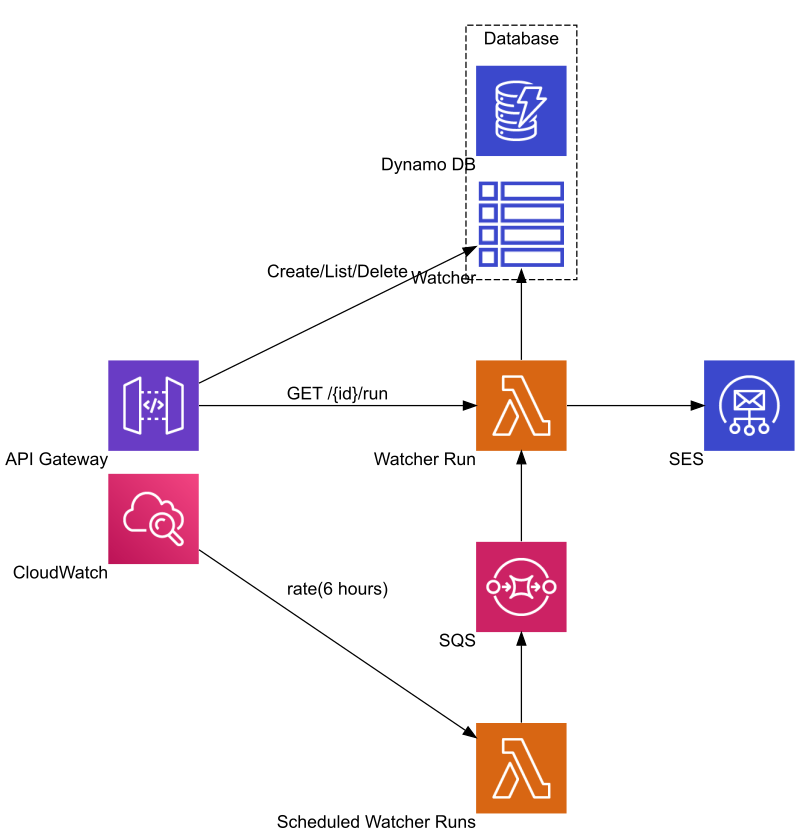
Watcher is a simple productivity tool to check for changes on websites. Create individual watchers by setting the location (URL) for the page and path (XPath) for the content to monitor. The application then checks for any change in the content every 6 hours. It is an API first and API only application with 4 endpoints: create a watcher, list watchers, delete a watcher, test run a watcher.
AWS is in many ways the front-runner of Serverless and their Lambda service is one of the leading Function as a Service (FaaS) engine. Node.js is a frequent choice of language for FaaS implementations and I wanted to see how it would compare to Python. I was keen to use as many of the readily available functionality and services as possible, and write as little infrastructure code as possible (not to be confused with infrastructure as code).
Getting started
Serverless is full of infrastructure configurations, also known as infrastructure as code. It was a decision from the beginning that everything goes into code, no (Web) console monkey business in the final result. Wiring up and configuring the services in code (YAML) has a bit of a learning curve, and comes with a few surprises – more about these later. Production ready code requires a good amount of DevOps skills, there is no way around it with this architecture.
Other than picking the right language and suitable libraries there is not much else for the main logic. As for the infrastructure code, there are far too many options available.
Native cloud scripting, templating AWS has CloudFormation and its sister SAM
General purpose scripting and templating Terraform and many others
The choice was to go with SAM and drop into CloudFormation where necessary. Ultimately all the solutions will have a straight line down to the platform SDK. The main question with 3rd party solutions is, how well and close they can follow platform changes? Do they support the entire platform and all the attributes needed?
Operating a platform in actual code lacks abstraction and too verbose. Native platform scripts and templates offer the right level – close enough to the platform SDK for fine grain control, but well above in abstraction to be manageable. SAM as a bonus can raise the level of abstraction further to make life even easier. If there is a future for infrastructure as code it must be to do more with less code.
Other projects with different conditions may find the alternative solutions more suitable.
A quick prototype probably makes better use of a toolkit like Serverless Framework.
A large scale, multi-provider cloud environment could use a general purpose engine like Terraform.
An adaptive environment with lots of logic in provisioning resources would need a coding approach like Troposphere.
Designing the application
Given the service oriented nature of Serverless and FaaS, a service definition seems to be a good start. Swagger (OpenAPI) is a good specification and has good platform support on AWS and in general. Another reason for choosing SAM templates was the reasonable level of support for Swagger.
Swagger specifics
SAM does not handle multi-part Swagger files at the time of writing this article, which would be an issue for a larger project. One solution could be to use a pre-processor, something like Emrichen which looks very promising.
Unfortunately the platform specifics and infrastructure as code leaks into the API definition, there is no easy and clean way around it. Therefore the Swagger definition is peppered with x-amazon- tags in support of the AWS platform and SAM. Perhaps the right pre-processor could merge external, platform-specific definitions in an additional step during deployment.
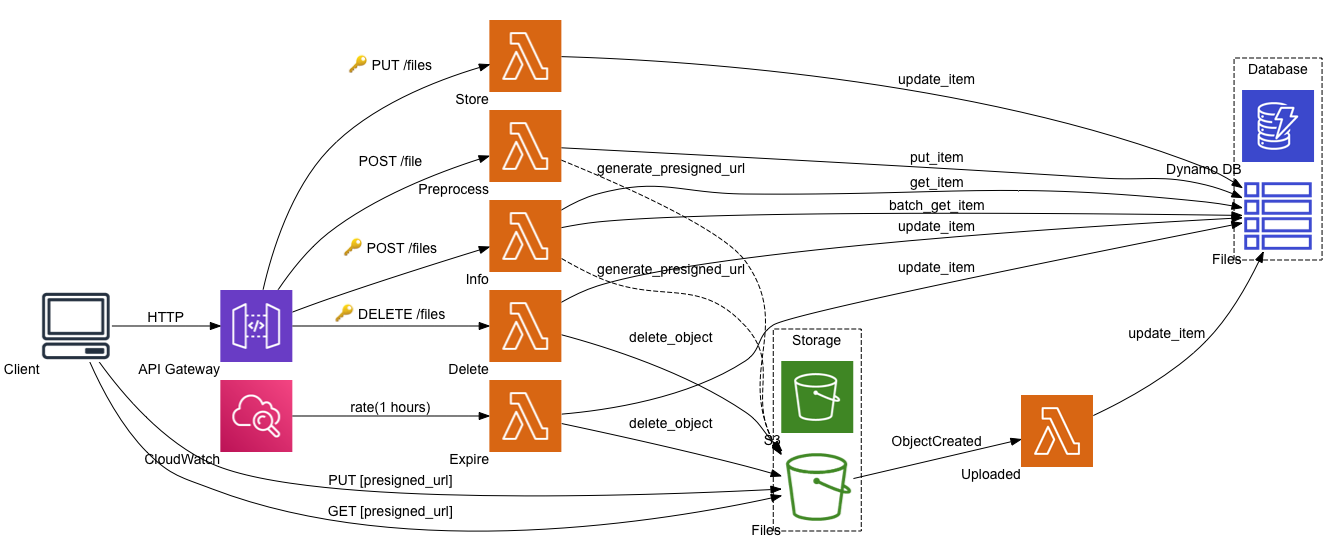
Platform services
Here is a high-level diagram of the AWS platform services in use in the application. Lot more relevant bits could go onto this diagram that are not trivial at first – more about these later.
API Gateway was a given for reaching the REST API-s in the application. DynamoDB can easily meet the database needs. It is also easy to expose CRUD + Query functions via the API Gateway. Lambda was the primary candidate for the two services doing most of the work for the application. CloudWatch has a scheduler function that comes in handy for triggering the regular checks. Fanning out the individual checks can be done using a queue mechanism, SQS does the job well. Finally, notification e-mails go out via SES.
Cross-cutting concerns
This project was specifically avoiding getting into cross-cutting concerns such as application configuration, security, logging, monitoring. They will be explored in another project.
Application configuration uses environment variables set at deployment time.
Security uses simple API key authentication. The implementation uses IAM’s roles and policies to authorise access, but it does not follow any recognisable model or method at this time.
Logging and monitoring was not explored in any detail. The first impressions of the vanilla logging facility were poor. The lack of out of box aggregated logging is a big surprise.
Building the application
Database (as a Service)
DynamoDB is a versatile key-value store with built-in REST endpoints for manipulating the data. I was keen to make use of the built-in capabilities and see how far they stretch. While DynamoDB does the job for this project, it will be increasingly more laborious to use for even slightly more complex jobs.
My very first task was to hook up DynamoDB operations to the API Gateway and be able to create new items (records), list them, and delete them without involving Lambda. It is all configurable in Swagger with relative ease.
Observations
I could not return the newly created item in the response to the client. There is no support for ALL_NEW or UPDATED_NEW in ReturnValues for the putItemoperation, so now the API returns an empty object with a 201 status.
Mapping templates (request and/or response) in Swagger look like code in the wrong place.
Mapping actually uses another template language – Velocity. An immediate limitation I hit was trying to add a timestamp to the created_at attribute. There is no way to insert an ISO8601 UTC timestamp. The solution was to use $context.requestTime, which is CLF-formatted. The only other alternative would be Epoch.
AWS Lambda in JavaScript (Node)
There are two functions implemented on Amazon Lambda:
Checking a single item, web page, for any change.
Periodically getting the list of watcher items and launching individual checks.
The code is fairly simple and self-explanatory for both functions, see comments in source code for more detail on GitHub.
Coding Lambda functions in Node/JavaScript was a breeze. Adopting the function*() yield combo in the programming model makes it very easy, sync-like, to code in this inherently async environment. Defining the functions in SAM is straight-forward.
I managed to focus on coding the application features without much distraction from infrastructure code. The one task that did not work well was manipulating data in DynamoDB. AWS SDK is too low level, it would not be efficient to use on a larger, more complex project. Next time I would definitely look for a decent ORM library, an abstraction on top of the SDK, something like Dynamoose.
The AWS SDK is bundled with the Lambda runtime. It does not need to be a dependency in the package.json, it can be a development dependency only.
Application integration
Every once in a while – set to 6 hours by default – one of the Lambda functions retrieves the list of watcher items to check for any change. There are a few different strategies to overcome the restrictions of Lambda function timeout, fanning out the check function seemed an easy and cost effective way to go. Each item from the list is passed to an SQS queue in a message, then picked by the target function. A few considerations:
Messages are processed in batches of 1 to 10 depending on the configuration. This use case needed to process only 1 message at a time.
If the check fails for any reason, the message is put back into the queue and retried after a short while. Set a maximum number of deliveries on the message to avoid countless failed function calls and associated costs. Another control mechanism, for other use cases, is to set the expiration on undelivered messages.
Worth defining a dead letter queue where failed messages are delivered after all tries are exhausted or timed out.
Queues resources are not available in SAM, had to use CloudFormation AWS::SQS::Queue definitions.
The wide range of event sources supported by Lambda is very powerful. Be aware that event sources can have very different looking event data and determining the source from either context or event is not trivial.
One of the Functions – run-watcher – can be invoked via API Gateway and via SQS message. These two sources have entirely different message schemas. A small code piece is responsible for detecting the source, based on event specific attributes and parsing the message accordingly. In an ideal world, the AWS infrastructure would provide explicit information about the source of the different events.
SAM’s intricacies
The aforementioned scheduling of periodic checks was done using the AWS CloudWatch Timer service. This was easy enough to configure in SAM as an event on the Function.
SAM’s ability to create resources as necessary is a double-edge sword. While it significantly reduces the amount of infrastructure as code, it also introduces surprises to those who are not intimately familiar with all the platform specific resources of their application.
The scheduler resource is a good example to investigate. In SAM the scheduler event was defined in 4 lines as
The SAM version is ultimately expanded to the same CloudFormation definition by the tool. Notice that in SAM there is no place for some of the properties found in the explicit CloudFormation definition. This is why many of the resources generated by SAM behind the scenes will show up with seemingly random names. A good summary of generated resources by SAM is on https://awslabs.github.io.
This behaviour is not limited to SAM, many 3rd party tools that use an abstraction on top of CloudFormation have the same effect.
Resources depend on other resources. In most cases dependencies are satisfied with inserting a reference to the resource using their name or their ARN. When creating the individual resources part of a stack, some of the references may not resolve because the pertinent resource do not exist yet at the time. The resolution to this problem is to explicitly state dependencies in the template. The usage plan (AWS::ApiGateway::UsagePlan) in the SAM template is a good example to analyse.
Trying to deploy the stack without the explicitly stated dependency DependsOn: WatcherApiStage will fail with not finding the Stage which is automagically generated by the SAM template together with the API (AWS::Serverless::Api) later. This case is further complicated by SAM’s abstraction of API resources and hidingthe Stage resource definition. Where is the name WatcherApiStage coming from? It is generated by SAM as described at this link.
The SAM CLI has a validation function to run on the SAM template, and the Swagger API Definition. The current validator has little value, failing to catch even simple schema violations. The true validation of the template happens when CloudFormation attempts to build the stack. In the future, infrastructure as code must have the same level of syntax and semantic check support as other programming languages.
Cross-over between infrastructure as code and application code
Occasionally the the application code must share information with the infrastructure as code. For example: the ARN of the queue where the application sends messages to. In this case, SAM has an environment variable for the Function that picks up the queue ARN using a utility function (GetAtt). The environment variable is read during execution to get the queue ARN for sending messages. This works well in most cases where infrastructure definitions are made in one place only and picked up during deployment, and the references do not change after deployment.
Setting the region for SES is a similar case, but warrants a short explanation. SES is only available in 3 specific regions and the application must use one of those for sending e-mails even it is deployed elsewhere. There are no SES resources (AWS::SES::…) defined in this project, yet the SES region is defined in SAM as an environment variable. It could have been a configuration in application code, but since SES is an infrastructure element, the region configuration is best placed in SAM.
Summary
The application works, it does what it is supposed to. There were some trade-offs made and there are areas for improvement. But most importantly the architecture and the platform has huge potential.
Building the application was easy enough. Was it as easy as on Google App Engine? That is for the next time.
while the fate of a few are unknown (memcache, search).
There were a mix of changes on the (Standard) platform:
Version 2 runtimes, auto-scaling containers (gVisor)
Move to REST API-s, away from the proprietary Google API.
These are generally welcoming changes, and while the platform is in a state of flux currently, some of these changes have removed the comfort and ease of building software for the platform.
The search begins
Writing infrastructure code has eaten into IT projects for a long time. It causes all sorts of project slippages, budget overruns, and enormous technical debt.
Developing your own server – web, messaging, socket, even database – or building a new web application framework, or client library are all “writing infrastructure code”.
Therefore it is imperative that coding focuses on business capabilities and value with the new stack.
It also means we can do away with the server infrastructure – servers, VMs, containers. While we are at it, it should remove the associated scalability and availability concerns too.
Costs should align with business value, and include effective use only, for example: computing time (no idle), messages sent, users registered, data stored, files transferred, jobs scheduled, and so on.
The stack has to sit on a platform with a rich ecosystem – a good range of core services for example:
database,
object storage,
messaging,
identity management.
Some of the best in class capabilities could live outside of the platform, for example:
payments,
bulk and transactional emails.
The stack must have the facilities to gain insight into its inner workings. Support for variable levels of centralised logging from hosted services and from logging API in bespoke code.
Support for monitoring of platform and application services, alerting on specified issues and metrics.
There must adequate tooling support for the entire application lifecycle extended to
environments, including local development,
programming languages, including relevant tool-chains.
A worthy candidate
The emerging paradigm, Function as a Service (FaaS) together with Serverless, promises to meet my expectations. It would have to be part of a comprehensive cloud offering that delivers the rest of the stack.
FaaS/Serverless reinforces cloud native concepts, and that leaves a lot of questions open for this new stack.
There is still the Google App Engine Standard 2nd Generation with the rest of the services from the Google Cloud Platform. If it wasn’t for the challenges that prompted the search for a new stack, it would be one of the best options available. Perhaps it will be again some day. In the meantime, is there something better?
Is it going to deliver on the benefits? What are the trade-offs going to be? Let’s see.
The basic idea is to use Semantic Web technologies to support the Enterprise Architecture practice in the organisation. Semantic Web offers a set of capabilities that makes it ideal for this purpose.
What is available?
Semantic MediaWiki The current version (at the time of writing: 1.8.x) is a sufficiently mature implementation of semantic features on top of MediaWiki. There are a suite of extensions – most of them are part of the Semantic Bundle – available to extend the basic feature set.
Enterprise Architecture ontology The basis for enabling SMW to be used as an Enterprise Architecture (EA) tool is the EA ontology (call it meta-model, or schema). It defines a set of concepts and their relationships that will help to organise and structure the information gathered about the enterprise. One of these ontologies can be easily derived from the ArchiMate (V2) meta-model.
Triple storage for semantic inferencing and querying (SPARQL) Triple stores are a bit tricky in the current version of SMW. The main reason for using them is to take advantage of features like: symmetric properties and inverse properties, offering a lot of value when querying.
What else is needed?
Semantic Annotation Currently the weakest part of MediaWiki (not specific to SMW) at the moment is the editing, which is not helped by the additional markups for semantic annotation. DataWiki (formerly SMW+) a reasonable job with allowing semantic annotation on the wiki page in WYSIWYG mode. A decent annotation tool (perhaps porting DataWiki’s implementation) is needed to do this job better than the plain wiki markup in SMW. Note that most people solve this issue and prefer to use Semantic Forms to enter data. It is a good solution, but carries the danger of constraining information capture and limiting use (virtually turning SMW into SharePoint or an Access Database). This will require new development and/or porting of existing code.
Spreadsheet integration The reality is that most organisations still use and prefer Excel as the de-facto standard for gathering “somewhat” structured information. It is still the most effective way to request records of data (for example: application names, descriptions, owners, etc) and review of data in many organisations. This will require new development.
Visualisation tool Most people prefer visual representation of landscape, design, etc. and the preferred tool in most places is Visio.This will require new development.
The part in there that really caught my attention was about the common-place-book. The following historical quote from John Mason in 1745 makes the case for organised (retrievable) thoughts:
Think is not enough to furnish this Store-house of the Mind good Thoughts, but lay them up there in Order, digested or ranged under proper Subjects or Classes. That whatever Subject you have Occasion to think or talk upon you may have recourse immediately to a good Thought, which you heretofore laid up there under that Subject. So that the very Mention of the Subject may bring the Thought to hand; by which means you will carry a regular Common Place-Book in your Memory.
In the same chapter, the historian Robert Darnton is quoted on re-organising texts into fragments and removing the linearity of the text:
Unlike modern readers, who follow the flow of narrative from beginning to end, early modern Englishmen read in fits and starts and jumped from book to book. They broke texts into fragments and assembled them into new patterns by transcribing them in different sections of their notebooks. Then they reread the copies and rearranged the patterns while adding more excerpts. Reading and writing were therefore inseparable activities. They belonged to a continuous effort to make sense of things, for the world was full of signs: you could read your way through it; and by keeping an account of your readings, you made a book of your own, one stamped with your personality.
Later in the Serendipity chapter – another pattern involving accidental connections – the author mentions DEVONthink, a tool to manage and organize all those disparate pieces of information. DEVONthink features a clever algorithm that detects a subtle semantic connections between distinct passages of text.
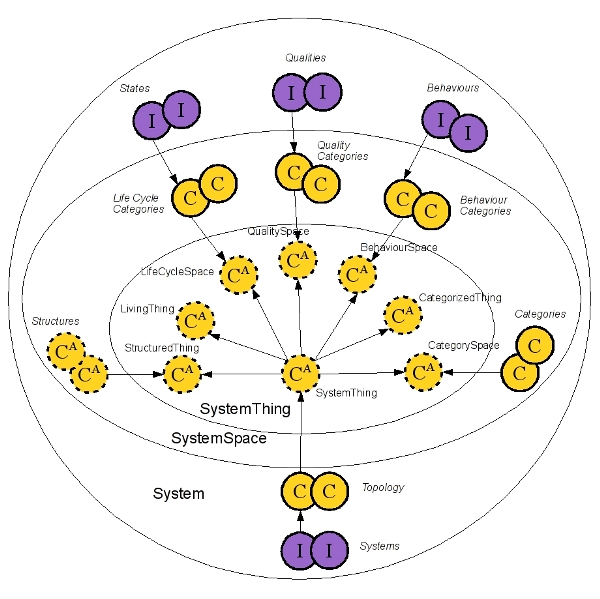
The purpose of the Systems Ontology is to provide a framework, in the form of an ontology, for capturing system details resulting from systems analysis.
The Systems Ontology is composed of three distinct parts:
SystemThing holds the core concepts of a system – not to be changed
SystemSpace is a definition of categories applicable to different concepts describing specific systems – should change rarely as the understanding of the different types of systems evolves
System is the place for the instances of specific systems – may change regularly as the analysis and understanding of specific systems progresses.
The following diagram is a representation of the different elements in each part.
Core concepts and Spaces Core concepts define the fundamental building blocks for the Systems Ontology in a set of abstract classes of mainly two types: Thing and Space. Things describe the different aspects of a system on very high abstraction level (meta-meta in this case). Spaces provide further refinement for the different aspects of a system.
Structure The structure of the system is described in abstract sub-classes of StructuredThing. The structure defines the relationships between concepts, it defines what form (in terms of graphs) of construct can be built. Constructs can be for example: chain, ring, tree, net, a combination of these or any other formation.
Specific structures are defined inheriting from the StructuredThing abstract class, making StructuredThing a collection, a container of various types.
An example structure: ComposableThing has two slots, has_part and is_part_of (both are each other’s inverse), since has_part is a multi-value, is_part_of a single-value slot referring to instances, the structure for ComposableThing is going to be a tree.
Category Categories are defined in the CategorySpace, which holds a hierarchy of categories underneath. CathegoryThing enables instances of a system elements to reference multiple categories from the CategorySpace.
CategorySpace is a bit unusual as far as modelling categories goes. Usually there is a meta-model for describing the characteristics of a category on the meta-model level then each category is an instance in the model often in some form of relationship with other categories. In this case, a different, perhaps unusual approach is taken when categories are defined as classes and sub-classes of classes. This will allows to build a hierarchy of categories and use the class name for the name of the category, which should be sufficient as no attributes are necessary. There is one more twist, instead of assigning a class (category) as a superclass to the categorized class, the CategorizedThing defines a slot with the value type of a class, in other words the category is defined as an attribute (slot).
This approach allows to define the categories in the meta-model in a hierarchy and still use them as an attribute in the model.
Life-cycle The notation of life-cycle makes the concepts “alive”, in other words, it represents the time factor.
Individual life-cycles are captured in the LifeCycleSpace as sub-classes. Life-cycles consist of states, these are captured as instances of a life-cycle class in the ontology. LiveThing enables the system instances to reference individual states and other related instances – behaviour and quality (details in the next section).
Note that life-cycles are not described as proper state-machines in this ontology. There is no notation of events or state transitions other than registering the preceding and following states for each state instance.
Behavior and Quality The following assumption was made: Only “living” things (ie concepts with life-cycle) show characteristics of behavior and qualities. Based on this assumption, behaviour and quality details can be registered to any LivingThing.
Behavior and Quality are two concepts represented in the ontology in a similar fashion. BehaviorSpace consists of sub-classes, where sub-classes are considered as categories of behavior. These categories can serve as a mechanism to group, qualify, arrange the long list of different behaviors a system may have. Specific behaviors are captured as instances of a Class from the BehaviorSpace.
Qualities are represented the same way, where categories are sub-classes of the QualitySpace and specific qualities are instances of a class from the QualitySpace.
System instances The root for capturing specific system instances is SystemSpace, it inherits a set of abstract classes (LivingThing and CategorizedThing) describing a system.
Besides creating instances for system elements a few other types of instances will be created along the way including: life-cycle states, behaviors and qualities.
States Life-cycles consist of states, individual state instances should be created under the relevant life-cycle categories. States are later referenced from system instances, where a system can only have one state at a time in the current setup of the ontology.
Behaviours and Qualities Behaviours and Qualities are instances of simple classes in the pertinent categories. In the current ontology each instance is represented with a name (slot) only. The categories should be carefully chosen for both set of concepts, otherwise can be time consuming to re-factor an instance of a quality into a category in order to register finer grain qualities. Same challenge applies to registering behaviour. Topology and Systems Systems, and sub-systems, are captured in some form of hierarchy in the ontology – the Topology. The Topology for systems is not pre-defined as it mostly depends on the method applied to systems analysis, and somewhat depends on the different types of systems as well. Topology is withing the System ontology, it is captured together with the system instances, unlike the categories for life-cycle, behaviour and quality.
System instances are created within the topology, where they automatically inherit characteristics of LivingThing and CategorizedThing. The topology does not have a notation of structure for system elements, therefore predefined (in the SystemSpace) structures should be applied as Super-classes to specific topology classes. Note that sub-classes in the topology will inherit structures from parent classes, for that reason structures should be used sparingly in classes closer to the root and should be applied to classes closer to the instances.
Data characteristics of system elements are defined within of the Topology by adding them to specific classes. Data details are essentially attributes (slots here) on a class. One should be careful making sure that data is not confused with structure. Slots with references to other system instances are perfectly valid data elements, however these can be easily confused with structure elements also represented as slots. The success of proper separation will depend on the rigour applied to systems analysis.